As intelligence and safety research continue to progress, I’ve been thinking more and more about how to create potential market dynamics that help with alignment and safer usage of AI. This feels especially important as we likely face cat and mouse games with frontier models pushing performance first and alignment/red teaming second, along with open source continuing to keep up (on a 3-9 month lag) with frontier models.
The traditional approach to AI safety has largely operated through the paradigm of technical constraints and social responsibility; a framework that, while noble in intention, often positions safety as friction against the relentless momentum of capability advancement. This has of course led to signals of alignment researchers concentrating more at certain labs, as others implicitly have voted slightly against alignment/safety with their dollars/compute allocations.

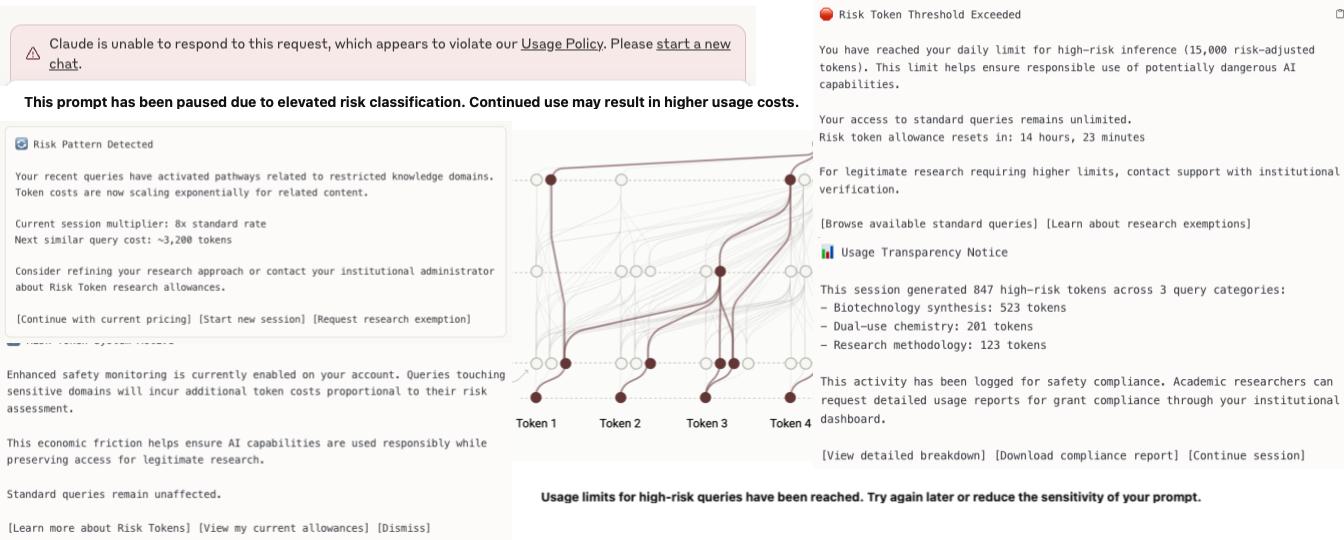
While the pace of research in AI safety continues, there have not been many approaches that tie together economics alongside safety breakthroughs. With this in mind I would like to bring forward our concept of Risk Tokens. Risk Tokens are effectively the classification of inference from AI models that are particularly risky to the world, paired with dynamic economic pricing that makes dangerous use cases naturally self-limiting through market mechanisms.
The inspiration for Risk Tokens comes both from the research we’ve done at Compound around biosecurity, anchored by the popular idea of frontier models potentially posing breakaway risks in bioterrorism or bioweapon synthesis, as well as from the concepts of crypto economics.
The biosecurity domain offers a particularly salient parallel, where biotech’s increasing power and democratization present a dual-use dilemma. Just as the CDC and USDA maintain tiered access controls for select biological materials, access to potentially dangerous AI capabilities could involve similar economic and procedural friction. It’s likely this will only cascade further as we see more decentralization of lab work through cloud labs, and a lowered barrier to science broadly through frontier models (and even tacit knowledge that can be learned through youtube.)
Crypto offers perhaps a more elegant mechanism and parallel. In Bitcoin’s design, network security emerges from making attacks economically irrational. The cost of executing a 51% attack on the Bitcoin network which currently requires hundreds of billions of dollars worth of hardware and electricity, renders such attacks self-defeating.
Similarly, Ethereum’s gas fees serve a dual purpose: they price computational resources to prevent spam while creating a natural auction mechanism for network priority.
Solana’s experience provides another example: when transaction costs were too low, the network suffered from repeated spam attacks that degraded performance for all users, demonstrating that purely technical solutions without economic friction often fail at scale.
These systems all show that when you align economic incentives with desired behaviors, security becomes an emergent property rather than an imposed constraint.
One could imagine two ways in which you could structure Risk Tokens such that in order to run inference on areas deemed “high risk”, the user pays more. This behavior of “pay more for better knowledge/inference” feels off but is already seen in usage limits applied to models like Opus vs. Sonnet or in creative focused models that charge varying tokens based on output resolution or quality.
This simple structure would effectively internalize the potential negative externalities of potentially dangerous AI model us.
A simplistic approach using prompt and output analysis
A first-order more simplistic approach for Risk Tokens could work as follows:
The company serving the model would classify a given prompt and output as risky and charge on a token basis for higher usage patterns.1This of course happens at the model layer in some forms already and companies like Cloudflare also have APIs as well. This concept is in-line with Anthropic’s Constitutional Classifiers research, where AI models are guarded by input and output classifiers trained on synthetically generated data, defining allowed and disallowed content based on a set of principles. This, along with a bunch of other alignment work being done which we’ll talk about, allows the model to actively filter out potentially misaligned use.
An example in bio could show a query about general protein folding carrying standard inference costs, but a query that discusses toxin synthesis or viral gain-of-function research, or cascading prompts that generate refusals/run into these areas that attempt to circumvent safety guardrails, would trigger exponentially higher token costs.
Of course, this might not work in the current paradigm of frontier models due to unlimited usage subscription tiers, but you could imagine a world in which metering or increasing prices of risk tokens would make it such that you could have higher awareness when someone spams the network and spends large amounts of money. At a minimum allowing for better mid-usage awareness that is not tied to pure AI Alignment research but instead a far more legible and low-cost identification mechanism of dollar spend.
Put simply, Risk Tokens in this scenario serve multiple purposes beyond deterrence, including audit where high-risk usage leaves financial fingerprints, better rate limiting for risky behaviors such as jailbreaking attempts, and most importantly, it puts an economic barrier on adversarial use.
Recent red team exercises show successful jailbreaks often require 50-500 attempts and it’s likely this could increase. With current pricing dynamics at the API level, these types of attacks cost single digit dollars. Under exponential Risk Token pricing, the same attack sequence could cost hundreds or thousands of dollars, fundamentally altering the economics of exploitation. Each failed attempt, or successful but risky query, would increase in cost, creating a natural exponential backoff that makes brute-force approaches economically prohibitive.
Lastly a system that purely tracks the usage of Risk Tokens could contribute to a user-level safety track record, which may be relevant in a world where reputation systems could influence an entity’s access to resources.
Circuit Traces & The Next Frontier of Risk Tokens
The second, more sophisticated approach to implementing Risk Tokens relies on fundamental breakthroughs in our ability to understand AI’s internal workings, often referred to as mechanistic interpretability.

This deeper interpretability has a particular mechanism that stood out called Circuit Tracing.2I highly recommend listening to Dwarkesh talk with Sholto Douglas and Trenton Bricken on this.
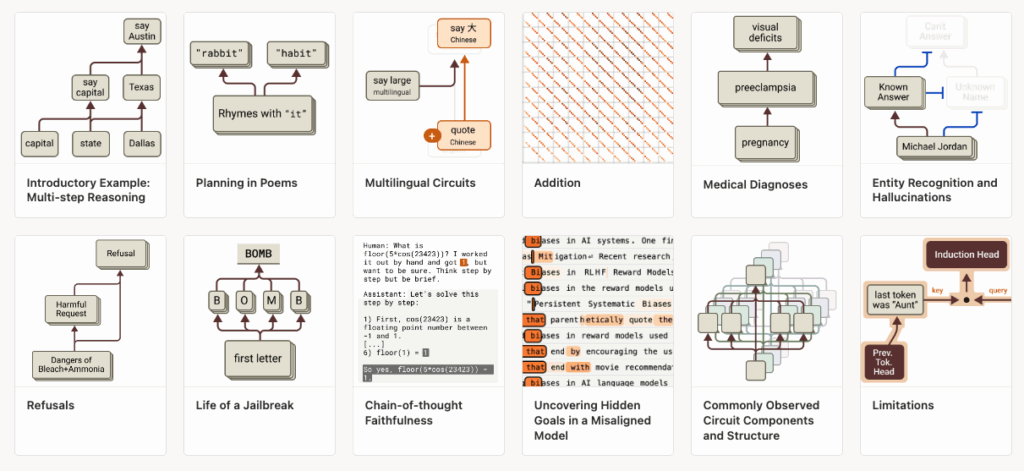
The core idea is that by observing the internal “traces”, the pathways of neural activations and conceptual processing, we can identify when a model is traversing potentially dangerous reasoning patterns en route to an output.

The diagram above shows a simplistic framing of this principle but the main point is that as long as we are able to understand the core features in given combinations of neurons, we can understand model behavior internally that can help against sophisticated jailbreaking techniques.
Today it currently takes a few hours of human effort to understand circuits with short prompts, but one could imagine this as a secondary (or primary) defense once done through automated interpretability systems.
For example, when a model processes a query about synthesizing a novel pathogen, the model could observe the specific neural pathways being activated, the conceptual territories being traversed, and the knowledge clusters being accessed. Each of these traces could carry risk signatures which could then be quantified and priced.
This query of ‘tell me about the increasing transmissibility of respiratory pathogens’ might traverse: ‘viral replication cycles’ → ‘mucosal immunity evasion’ → ‘aerosol stability optimization’ → ‘host cell receptor affinity enhancement’ → ‘immune suppression mechanisms.’ This cascading activation pattern, particularly when combined with traces touching ‘environmental persistence’ and ‘cross-species transmission,’ could trigger exponential token cost scaling.
This would result in making it economically disadvantageous to repeatedly probe dangerous areas of a model’s knowledge. This offers a shift from binary access control (allowed/refused) to a more nuanced, gradient-based economic friction that preserves legitimate research while deterring misuse.
One could imagine that trace-based analysis could capture emergent risk in queries that appear benign individually but become dangerous when combined or processed in specific ways.3Risk Tokens under this framework would be dynamically priced based on a compositional risk score: the base rate multiplied by risk multipliers derived from input classification, trace depth through dangerous knowledge territories, and predicted output harm potential. Where traces touching multiple risk areas compound costs exponentially, creating strong economic disincentives against synthesizing knowledge from multiple dangerous domains.
This also could, in-theory, result in an audit mechanism where third-parties could look at how many times high risk tokens were generated through a given API, allowing people to understand which models were being abused/used most.
Challenges and the Path Forward
Again, in exploring the bleeding edge of alignment I have not come across a mechanism with both technical and economical barriers but if there are others, I welcome feedback.
On first glance the core technical challenges I see largely surround technical overhead related to cost, latency, and ability to process complex prompts.
Ignoring the belief of some that “we should all be able to use AI models for whatever we want”, the economic mechanisms also of course creates usage concerns around areas that should be researched.4Of course, over time one could argue we will have local models that can do all of this but we’re not quite there yet and that doesn’t mean we should just throw our hands up in the air. Risk Tokens could create stratified access where only well-funded institutions can afford certain research and experiments. One could solve this with Risk Token allowances and grants for a variety of institutions and individuals.
From an implementation perspective, the path forward likely involves starting with narrow, high-consequence domains where the risk-benefit calculus is clearest. Again, biology is a natural point both due to the zeitgeist and the well-understood risks both on a 1-1 basis as well as a 1-to-many basis via things like autonomous science that could have safety benefit from economic friction, not dissimilar from circuit breakers in financial markets.5There is some research on AI safety and circuit breakers too.
On the recent Dwarkesh podcast Trenton Bricken of Anthropic said this as it relates to mechanistic interpretability and alignment broadly:
First of all, I’m not saying you shouldn’t try the probing approach. We want to pursue the entire portfolio. We’ve got the therapist interrogating the patient by asking, “Do you have any troubling thoughts?” We’ve got the linear probe, which I’d analogize to a polygraph test where we’re taking very high level summary statistics of the person’s well-being. Then we’ve got the neurosurgeons going in and seeing if you can find any brain components that are activating and troubling or off-distribution ways. I think we should do all of it.
While we are in this interim period, as we navigate dark forests of biological development with AI, and perhaps all frontier model performance broadly, doing so with both advanced interpretability and alignment alongside economic/market-driven incentives feels like the right path going forward.
- 1This of course happens at the model layer in some forms already and companies like Cloudflare also have APIs as well.
- 2I highly recommend listening to Dwarkesh talk with Sholto Douglas and Trenton Bricken on this.
- 3Risk Tokens under this framework would be dynamically priced based on a compositional risk score: the base rate multiplied by risk multipliers derived from input classification, trace depth through dangerous knowledge territories, and predicted output harm potential. Where traces touching multiple risk areas compound costs exponentially, creating strong economic disincentives against synthesizing knowledge from multiple dangerous domains.
- 4Of course, over time one could argue we will have local models that can do all of this but we’re not quite there yet and that doesn’t mean we should just throw our hands up in the air.
- 5There is some research on AI safety and circuit breakers too.
Recent Comments