Author’s Note: There are a lot of (long) footnotes in this piece. While they aren’t necessary, they do add a layer of depth that may be interesting to some readers.
While on the surface we mostly just see large rounds and revenue or usage leaks, in reality AI companies are perhaps some of the most complex businesses we’ve had being built in tech in some time. Doing core AI model R&D necessitates a need to play 4D Chess around research communities, capital accumulation and deployment, talent acquisition, competitive understanding, and commercialization.
AI companies today find themselves in multiple cycles of R&D and commercialization, making an implicit bet that the millions or billions of dollars spent on R&D will eventually lead to market domination and massive scale years from now. This pushes these companies into a dark forest they must navigate, while stacking up R&D costs ahead of clear staying power for far longer than the vast majority of software businesses.
But to understand whether AI companies are embarking on a rollercoaster of capital deployment that is a Super Cycle, or a Euthanasia Coaster style journey, we must also understand the impending shifts that will drive all strategy over the next decade.
On Capital Deployment
AI companies building or adapting their own models today exist at a time in AI where the world understands directional progress, but has very mixed views on future tactical levers to progress. On top of that, the rate at which these views change is faster than perhaps any industry we’ve seen.
The industry is now maturing from a simple view on what drives performance (scale) to a more uncertain experimental state leading to explorations of other frontiers as many teams realize the capital requirements that necessitated the scale narrative.
And these frontiers must be explored as AI companies navigate a variety of factors related to capital deployment including:
- Fixed capital and supply constraints of compute means companies struggle to access state of the art performance immediately, and/or sign large upfront contracts in order to secure supply from providers. 1There are even some companies with large compute contracts that are still waiting for access to H100s. In addition, the multi-dimensional nature of these providers has people wondering if supply will continue to be a concern once the AI Battles really heat up as they reduce supply to bring compute in-house. This was pretty obvious in hindsight and I’m a bit mad at myself for not anticipating this threat.
- A war for talent where supply (while growing) is still somewhat scarce in ability to do things like work with large model infrastructure or innovate on specific types of models, in addition to managing these types of organizations. 2There are an increasingly growing number of researchers, so yes there are many elite ones, however I think the limiting factor may be as much about getting these things working in prod versus last cycle of AI when there was a small number of people able to do anything innovative on the deep learning side
- Potential land grab and breakaway dynamics which means foundation/proprietary model startups feel an existential threat in keeping up with and breaking the state of the art. This leads to large capital deployment on the company side in these moments where each “new model” or re-train or NewCo that emerges with incrementally better performance could be the one that erodes a company’s early flywheel. 3I think about this a lot as it relates to ChatGPT vs. Claude. The rumor is Claude was supposed to come out ahead of ChatGPT and OpenAI scrambled to push out ChatGPT. If Claude had come out first, would Anthropic be known as the premier LLM company today?
- A lot of venture capital being deployed into all types of competitors.
- A thriving open-source ecosystem (perhaps now anchored by META) both contributing and threatening many of the dynamics in which AI companies are built on.
Monetization & Distribution
Once a company decides on their core advantages, they then must navigate fairly novel dynamics related to monetization and distribution.
These include:
- A strong willingness by consumers to experiment with many different tools that give them ROI and to experiment with tools in an effort to “keep up” with their industry’s disruption by AI. 4I previously wrote about this dynamic in-depth in The Curiosity Phase of AI
- Industry incumbents working with startups earlier than ever, in an effort to capture ROI ahead of competition. This is perhaps the best argument for moving quickly and establishing a brand moat. The question is if this brand moat will be lasting, especially as a lot of pricing is currently not being optimized in an effort to achieve dominance and keep business models simple. 5There’s an entire other post to write about decisions around simple ARR to multi-seat + usage etc. in order to compensate for inference costs and juice early revenue, which we’ll talk about later
- Incumbent software providers seeing meaningful revenue growth monetizing their existing distribution with simple integration of foundation model APIs.
- Lower barriers to entry leading to death by a thousands cuts for products that deploy non-SOTA open-source models with hyper-narrow features.6One could argue this short-term is bad but long-term is good if you are a good product and applied AI team as it will ingrain a behavior that you don’t have to teach the market. I go back to my Claude vs. ChatGPT example in another footnote above though and would say this instead probably just erodes your narrative capture (and thus raises your cost of capital) because investors are dumb and consumers may just churn out and say “AI sucks for xyz” and re-engaging them will be materially harder.
These financial and commercialization factors are just the start of building a view on where the world is going in an effort to properly navigate the various idea mazes in AI over the coming years.
The commoditization curve
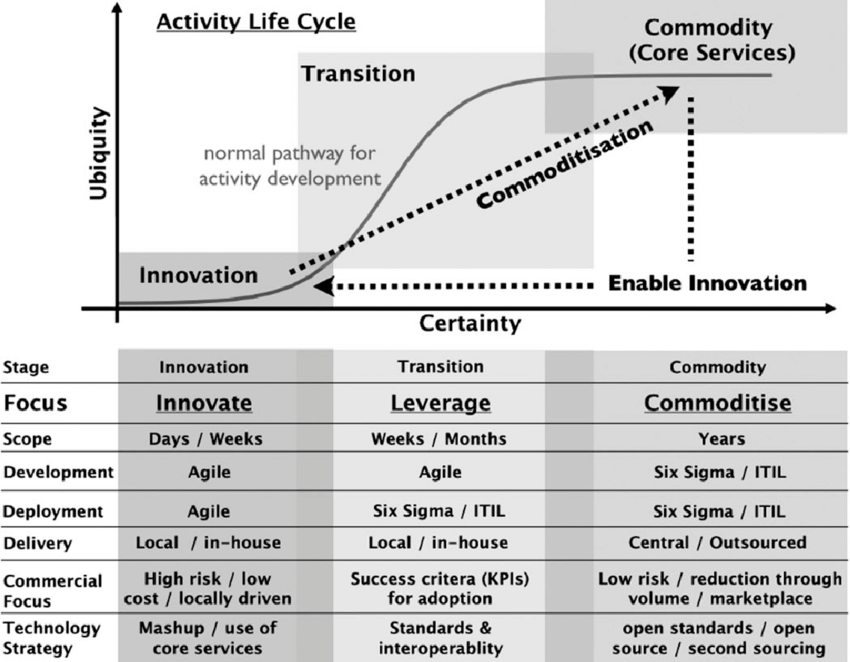
A core hypothesis all founders and investors must have around emerging technologies is the rate at which a technology commoditizes in order to dictate how to deploy resources at each stage of an emerging category. Within AI, there are various parts of the stack that could commoditize, creating both existential threats and moats.
The early cycle of AI companies were built7or maybe just financed under the premise that “the best algorithm wins”. In a world in which a small number of people could produce the “best algorithms”, this was thought to be defensible for a long enough time to build sustainable moats.
What we quickly saw a few years after AlexNet kicked off the previous hype cycle was that SOTA would instead be repeatedly broken in a world where models were now aggressively being built for narrow use-cases and the number of people studying the field exploded. 8Perhaps in retrospect the other learning was that reproducibility meant many papers were kinda bullshit, and scoping down use-case might mean low TAM and ROI.
We saw a commoditization in a variety of areas as performance reached human-level that led to the best competitive vectors being some form of easily integrated product and an ability to adapt to specific types of deep pocketed customers (like government). But there was still the joke of “machine learning is like sex in high school, everyone is talking about it but nobody is actually doing it” as few companies were able to deploy AI in product.
This led to an increased focus on “full-stack” businesses that could work with the narrowness of AI to add value to an incumbent business model or category and/or build a data moat. Companies such as AIFleet, Anduril, Palantir, Recursion, Wayve, and many others are examples of this.
With this cycle of AI we see far fewer dogmatic views, as the intricacies of LLMs has caused many to do the thing they always do when they have high conviction in a category but low conviction in specifics.
They invest in infrastructure.
Jon Luttig in his recent piece framed the bull case for foundation model companies (and bear case for infrastructure) well:
Much of the infra today is built to complement the limitations of LLMs: complementary modalities, increased monitoring, chained commands, increased memory. But foundation models are built via API to abstract away infrastructure from developers. Incremental model updates cannibalize the complementary infra stack that has been built around them. If only a handful of LLMs dominate, then a robust infrastructure ecosystem matters less.
Perhaps we will see a variety of “bank shot” wins in infra that start with solving near-term commoditized problems only to expand outward9As all DevTool for ML startups pitched from 2015-2020, or perhaps the cloud providers and other incumbents will continue to roll up these entities as we saw with MosaicML and Databricks.
My gut tells me however that as time goes on, the acquisition prices for these types of startups could fall after a first wave of build vs buy decisions are made by the cloud providers.
Application Layer Commoditization Strategies
The application layer however could have far different dynamics with a framework for commoditization likely sitting across a few strategies.
Deep/Frontier Tech businesses repeatedly attempt to dominate the commoditization curve by sequencing the cycle of R&D → Product → Distribution → R&D… properly to create a flywheel that spins so fast that it becomes incredibly difficult or expensive for a new startup to catch up. In some cases this means making sure you create step functions in R&D that still generate revenue in order to offset complexities of an R&D heavy and capital intensive business.10I wrote about this dynamic in companies like SpaceX in my prior essay On Inflection Points.
The narrative for this amongst AI companies today is that value can materially compound with things like RLHF, data moats, and capital moats.11At times I wonder if Sam repeatedly talks about raising tens of billions of more dollars for OpenAI in an effort to scare off competition and boil the ocean of investors to get them conflicted out My belief is that this is a short to mid-term solution that ends in the foundation model companies choosing to go down a few different paths:
1) Globalize
We could call this the OpenAI/Anthropic approach. Companies on this path aim to get distribution at a scale and rate that enables them to generate material revenue to offset the enormous costs of building highly performant, multi-functional models. This scale then can enable access to data exclusivity and perhaps creates the ability to pay for data at a rate that enables you to outspend many other players. To do this they’ll have to build the most powerful models consistently and create developer lock-in at the API layer and that there will be enough time in which their model is dominant so that it can compound to create this lock-in.
Capital and talent will provide a moat that forces them to compete with 1 of 5 players and the distribution of a general purpose platform will give them breakaway data moats for RLHF or other Alignment approaches.

The difficulty is that all of these players have this view and quietly say that they imagine a world where a few horizontal foundation models tackle multiple different verticals. I’m a bit dubious of any of the major players being willing to cede language-centric markets though as they continue to raise $2-10B+ cumulatively while going up against cash-rich incumbents ready to channel substantial capital into competition, but I could be wrong.

2) Opinionize
A subset of companies with perhaps more niche markets or defined products will push their model towards an opinionated output that becomes a dominant aesthetic and creates a brand moat. I discussed this in relation to Midjourney and Runway in my prior post on the topic of building opinionated AI products12Midjourney has gone as far as to implement a switching feature of RAW or Not in their settings that few people utilize but shows an awareness of this.

Entire companies could be built around this premise of injecting opinion as a way to combat technology commoditization. While these examples are very visual-centered, there are non-visual examples, such as creating bespoke personalities, as Circle Labs is attempting to do, or emotionally aligning your product, as Hume.ai, is doing, that could be valuable. These alignment decisions could lead to building a very strong flywheel that allows you to capture aesthetically-aligned partners’ data, while also building the brand moats mentioned above.
3) Verticalize
Many companies will go down the path of building core applications themselves in an effort to more tightly control the edge cases of their models, as well as spin their flywheel faster and faster and gain true network effects through their communities.
We’ve seen this in more narrow atoms-based areas like biotech and industrial materials, but it’s likely we see this in other bits-based ones as well. With this approach, founders must understand incumbent willingness to partner, durability of their product revenue, as well as value capture tradeoffs depending on the market and how much of the stack they want to control.
How AI Business Models Get Better

With an understanding of how companies evolve from a strategic and product perspective, we can then look at how technological shifts in AI could enable significantly more effective capital deployment.
On Infrastructure
As we talked about in the prior section, commoditization of adjacent areas will enable foundation model and Applied AI companies to potentially drive down costs surrounding infrastructure and back-end processes of these models.
This could manifest itself in companies no longer having to re-invent the wheel on a bunch of infrastructure, similar to the shift we’ve seen within TechBio, leading to better capital efficiency and pace of deployment, even if going “full-stack”.
This also should be a boon for a variety of second-mover horizontal model companies as well as vertically focused foundation model companies as acquiring talent in-house to build and manage this bespoke infrastructure for very large models will be less important. 13To the prior point on talent scarcity here, about a year ago it was estimated there were ~50-100 people in the world who were able to train a model (or collection of models) as large as GPT-4 from an infrastructure perspective. I’d imagine that was an underestimate but my gut would say a year later that number has maybe 5-10x’d
On Compute
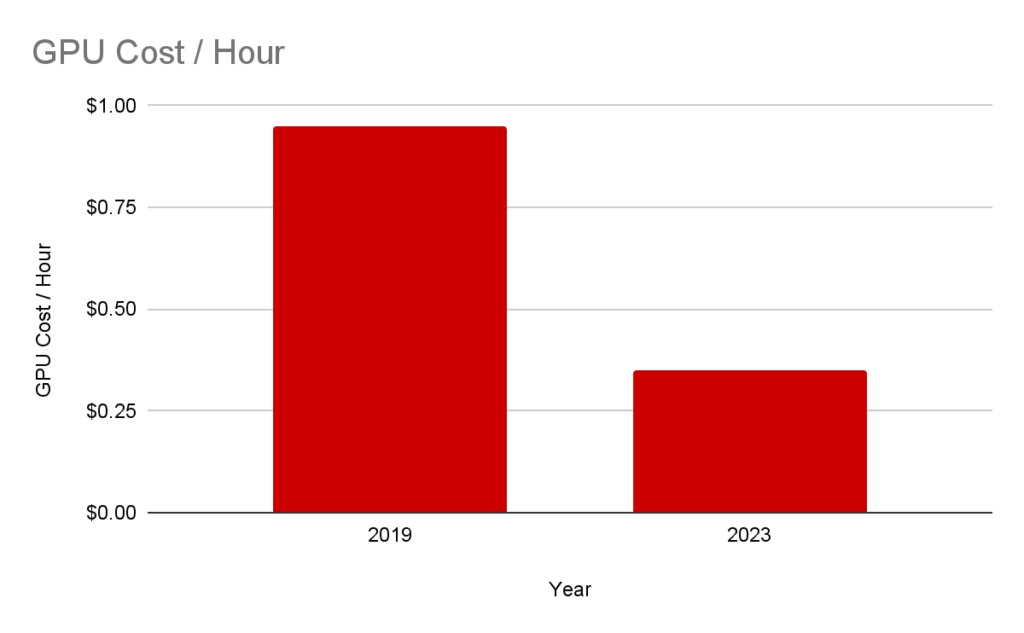
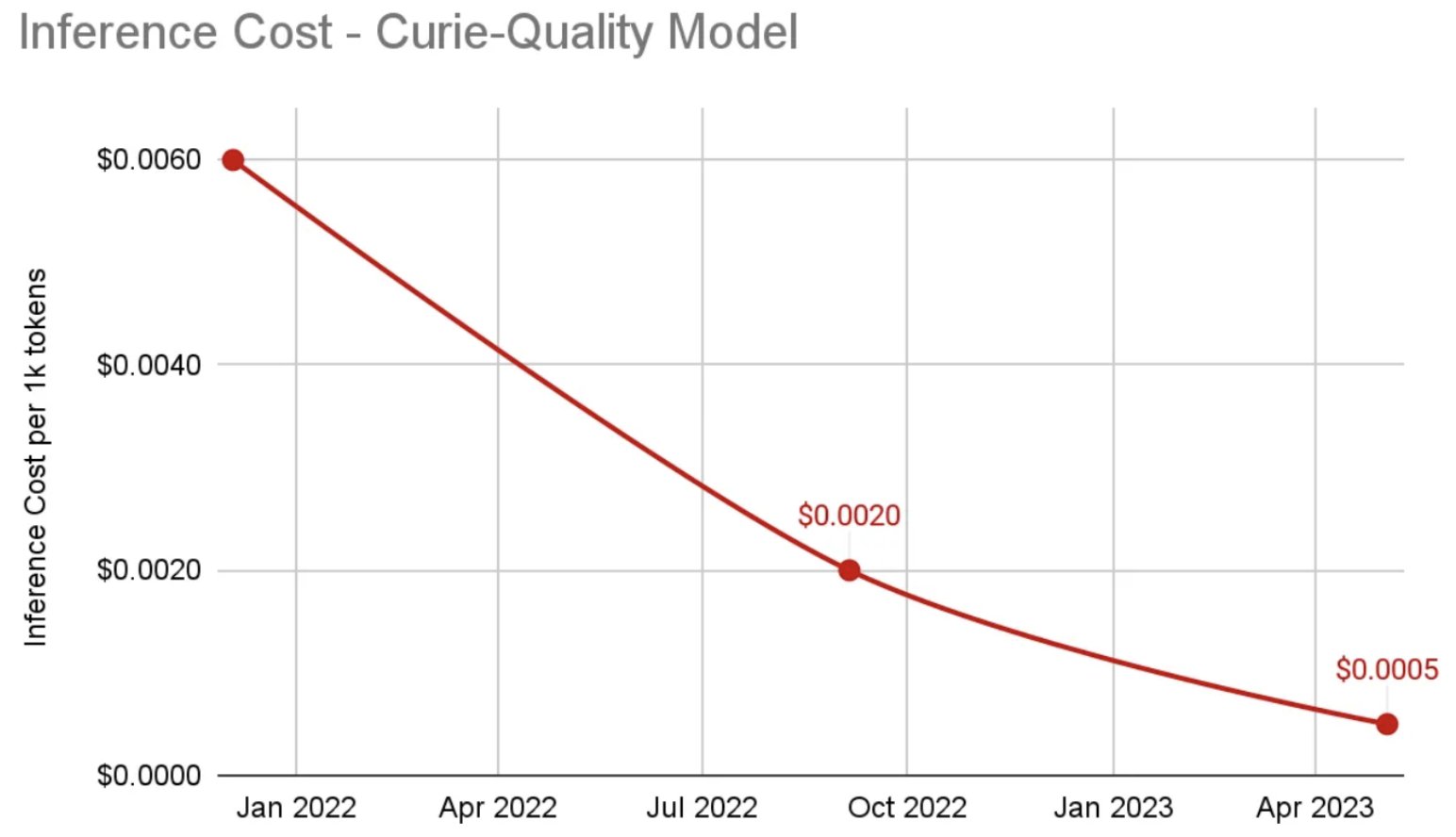
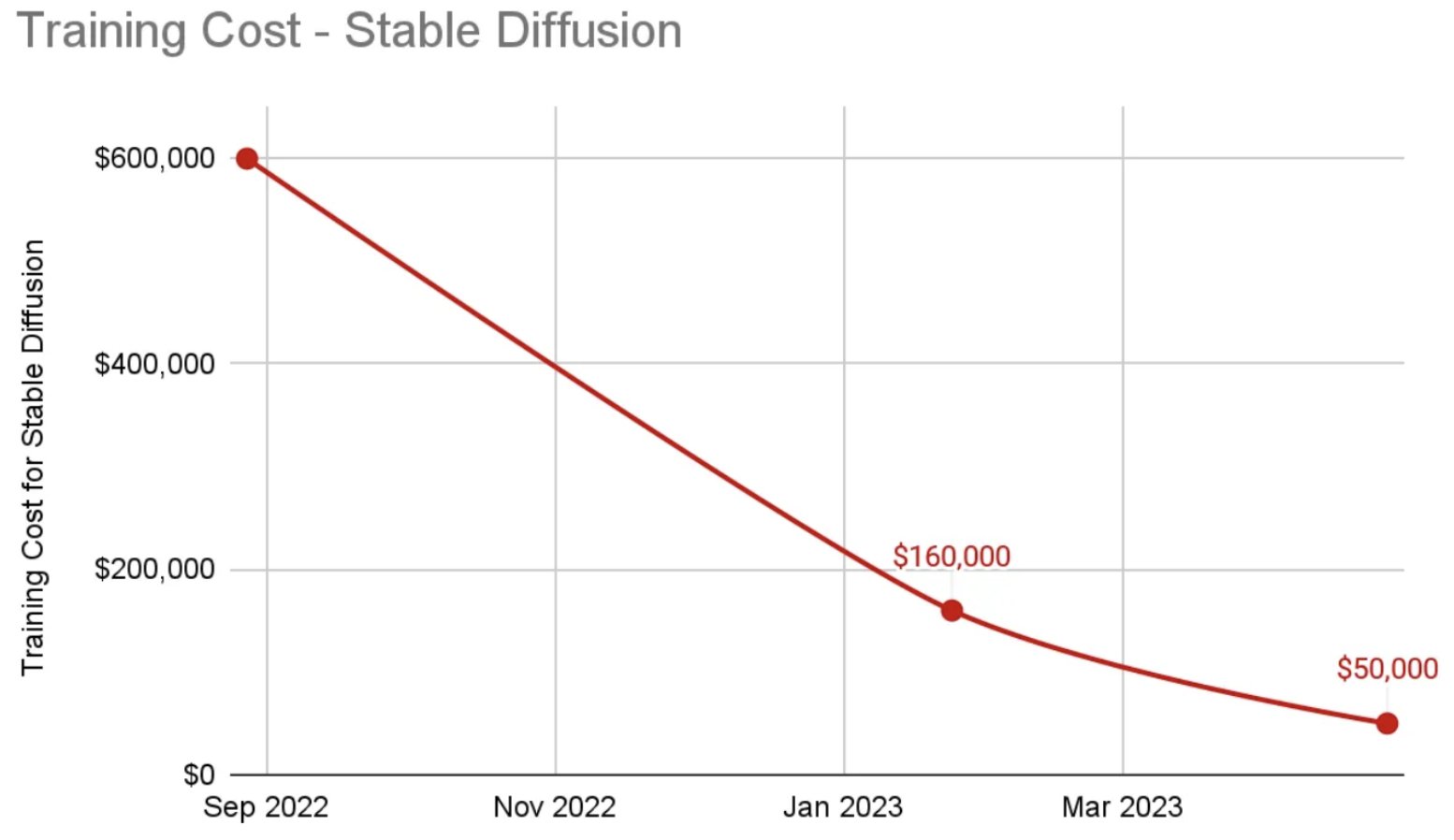
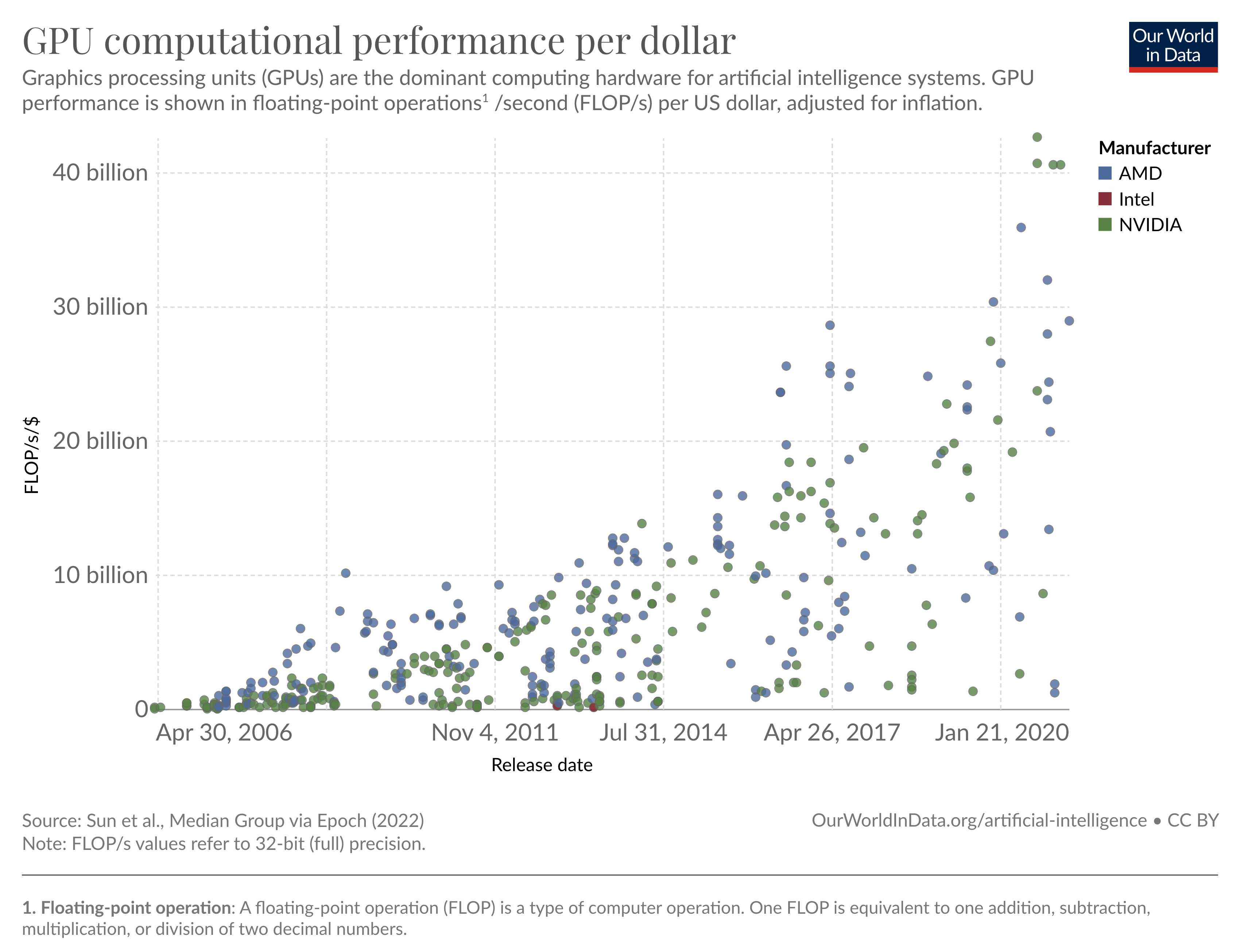
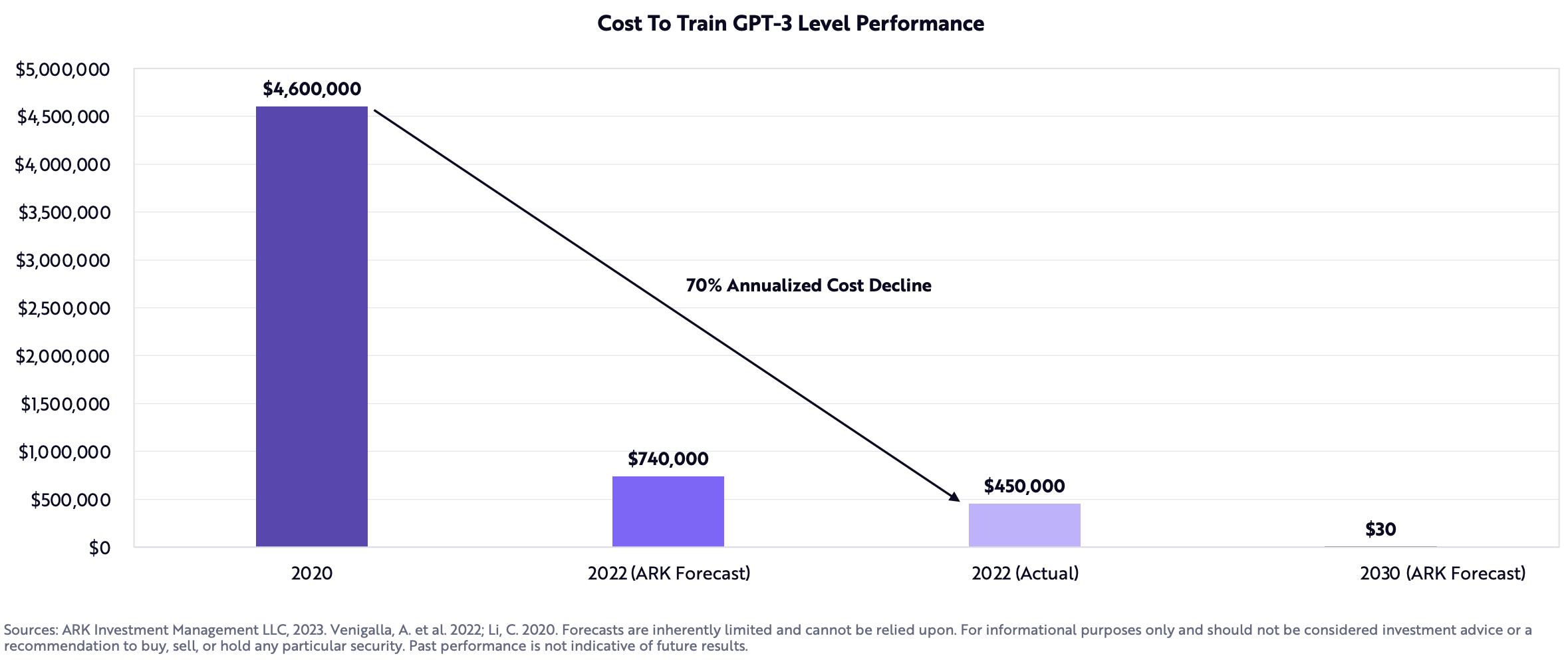
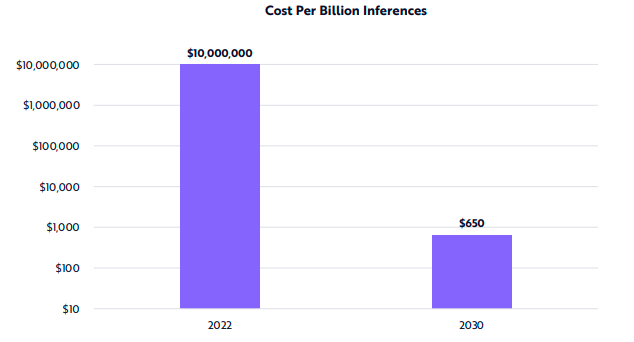
Today we can very simply look at the major costs of AI companies as Talent and Compute (Training & R&D + Inference). At this stage of the cycle, I’d barbarically smash together all Compute under R&D due to inference being such a core model improving behavior, however as companies get more mature, we will separate these and instead look at inference as a % of revenue.
The gallery above looks at a variety of changes in compute cost and performance over the past few years which could lead to mid-term margin expansion for both training and inference. These costs can be driven by more simplistic shifts, like cheaper and/more performant GPUs as more advanced hardware comes out (T4 to A100 to H100s), all the way to more purpose-built compute specifically built to work with larger models.14There’s a sea of startups building here in addition to the R&D companies like Amazon, Microsoft, Google, Apple, and more are working on. In addition, an increase of supply could come from decentralized networks as they shift GPUs from other industries like crypto towards AI, further driving down cost for inference or small scale training.
While this makes these companies more attractive financially than they once were, in the short-term I’d argue the most important thing to come from these falling costs is opportunity.
Opportunity to train more models, gather more data, scale to more customers, ship more tests, and in general have more time.
On Architecture & RESEARCH
While traditional cost curves are easier to understand, what is likely to create more step function changes in cost in the near-term are architectural and implementation innovations.
These could look like Sophia on the pre-training side, LoRA on the fine-tuning side, LongNet on the expanded context window side (pushing the limits of ROI on a given model), as well as other recent papers such as Robots That Ask For Help, Distilling Step by Step, SparseGPT, ZipLM, SpQR (+ 100s of others that will be published in the next year).
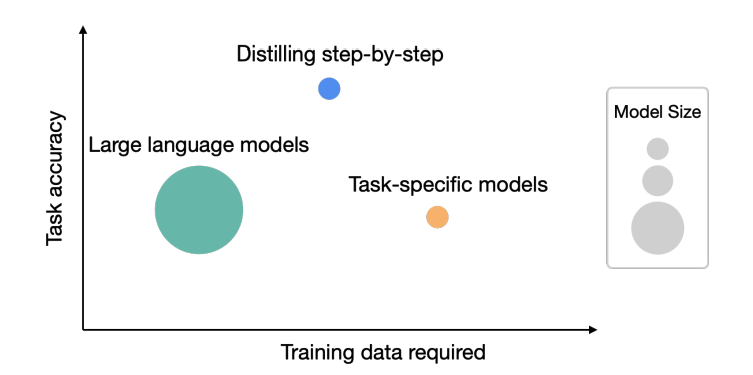
These technical innovations often start on the model & training architecture side and end where we go next, with data.
On Data
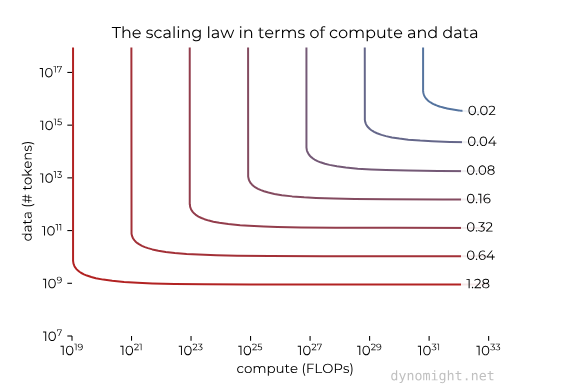
Some initial conviction in scaling up LLMs came from understanding and spotting the emergence of scaling laws in GPT-215This post by Dynomight is a great primer on scaling laws broadly. This led to a narrative and approach to building more performant large models being “throw compute and # of tokens at a problem.” This has worked fantastically over the past few years.
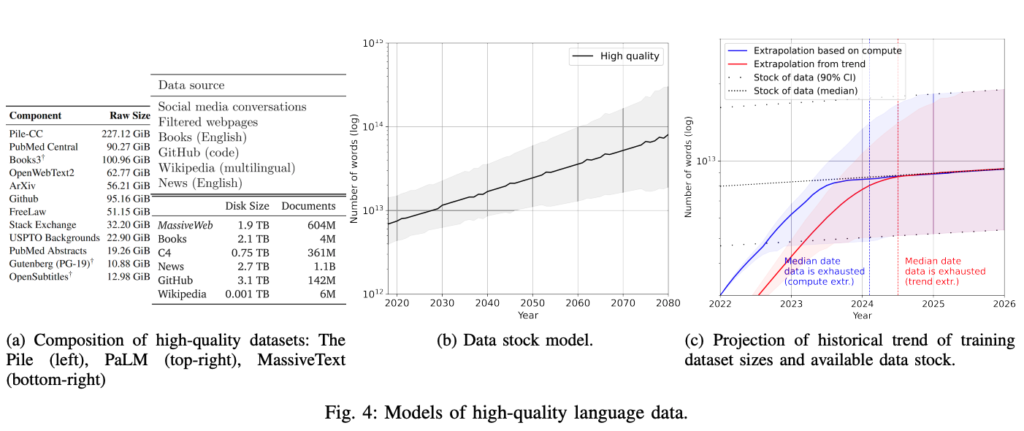
Now that we are beginning to see significant experimentation and maybe some upward bound on cost-performance tradeoffs for the world’s best models16I say this based off of comments around GPT-4s parameter size as well as some of Sam’s comments around when GPT-5 will begin training, new approaches are starting to take hold surrounding utilizing significantly better data, more efficient architectures, and smaller models.
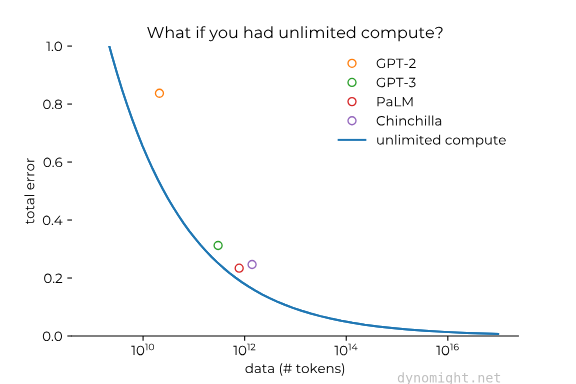
This approach could optimistically lead to the aforementioned lower costs on the compute side while also increasing performance. This also could end in a scenario where short-term margin savings on the R&D side get transferred over to data acquisition as companies such as Twitter, Reddit, Quora, and many others begin realize the value of the datasets they are sitting on and we continue to press towards ingesting the maximum available data.17Before everyone freaks out about synthetic data or using LLMs to generate more data, just know I’m not a “we are out of data” alarmist like some are. This is more about very high-quality, unique data.
A Note on Vertical Foundation Models & Data Flywheels
For more vertical foundation model companies, the early acquisition of data can lead to more proprietary data generation later on, again reducing costs of data acquisition that could increase performance, and expand margins and pricing power in the market.
This could manifest itself in startups working with flagship incumbents that have no ability to build these models themselves in the next few years, doing JVs first and then verticalizing further later. It also could be brute forced via early capex in facilities purpose built to generate novel datasets.
The Strategies for each type of AI Company
The point of this post is to look at the multi-layered game of company building in AI and understand the strategies that types of companies are building against and how they relate to each side of the capital cycle (Costs ↔ Revenue).18I know, it expanded a bit.
AI companies building their own models eventually end up in a few different core scenarios, with varying levels of success. Each of these scenarios depend on the myriad of factors above, but come down to a given company’s ability to generate meaningful long-term scaled revenue on the dollars deployed towards R&D today.
For each of these (very broad) scenarios, I attempted to model compute (training/inference) as bundled until year 5, where we then saw inference step down as a % of revenue from 20% to 5% over time. I also modeled strong revenue growth19because who cares about modeling mid outcomes? based off of private and public data I’ve seen across all types of AI Companies, in addition to blending some traditional SaaS revenue growth metrics.
These scenarios’ time horizon may be off (I think it’s very possible cost compression may happen far faster than modeled) and it is imperfect revenue data. In addition, the costs outside of R&D could begin to materially add up after the year 6 time horizon so while this isn’t a perfect look at how to think about burn rate, it is directional.
These charts allow us to look at the time in which the R&D feedback loop could begin to close for AI companies and to understand just how dark of a forest AI companies are navigating as they raise and deploy large sums of capital.
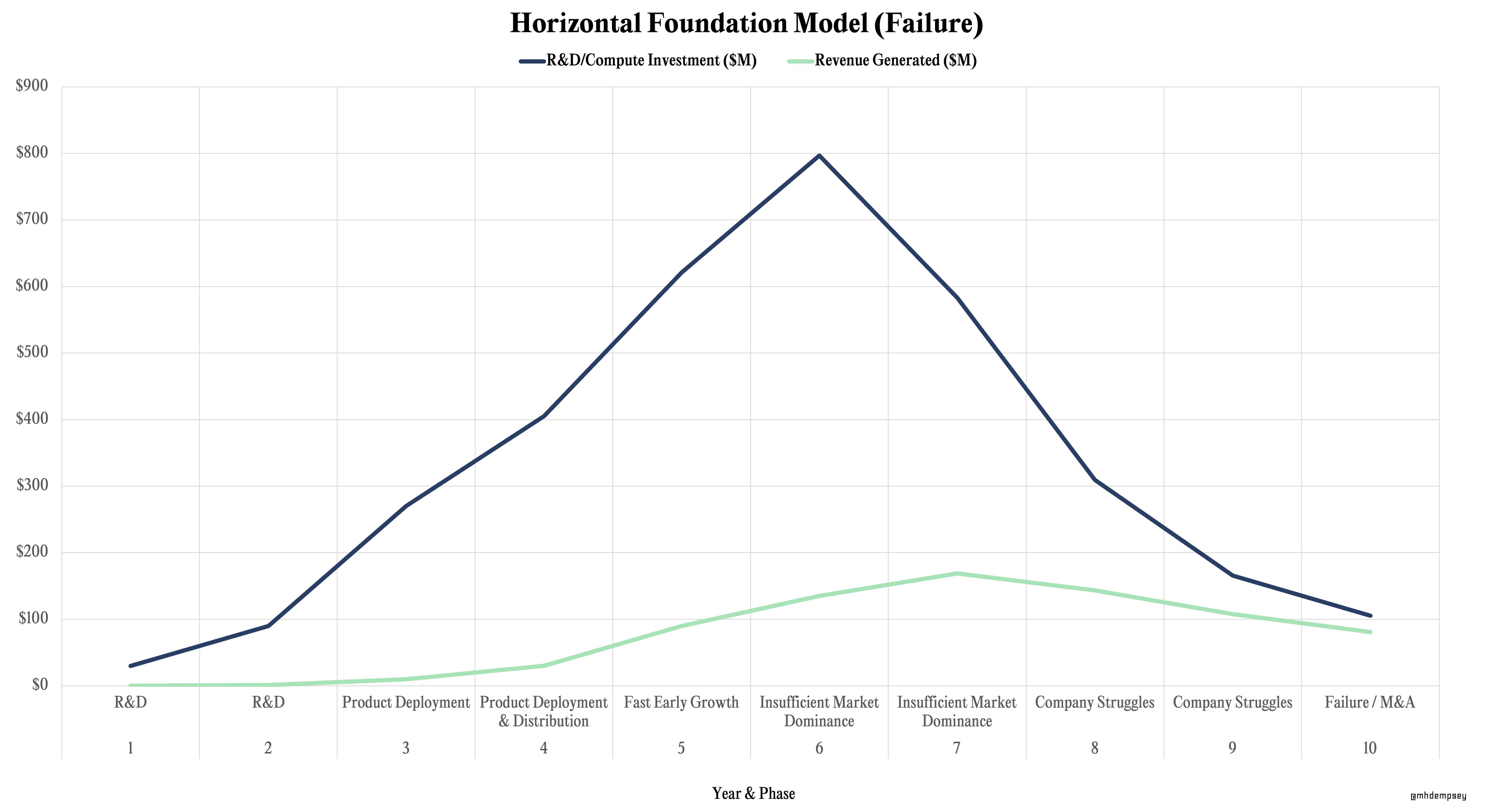
Horizontal Foundation Models
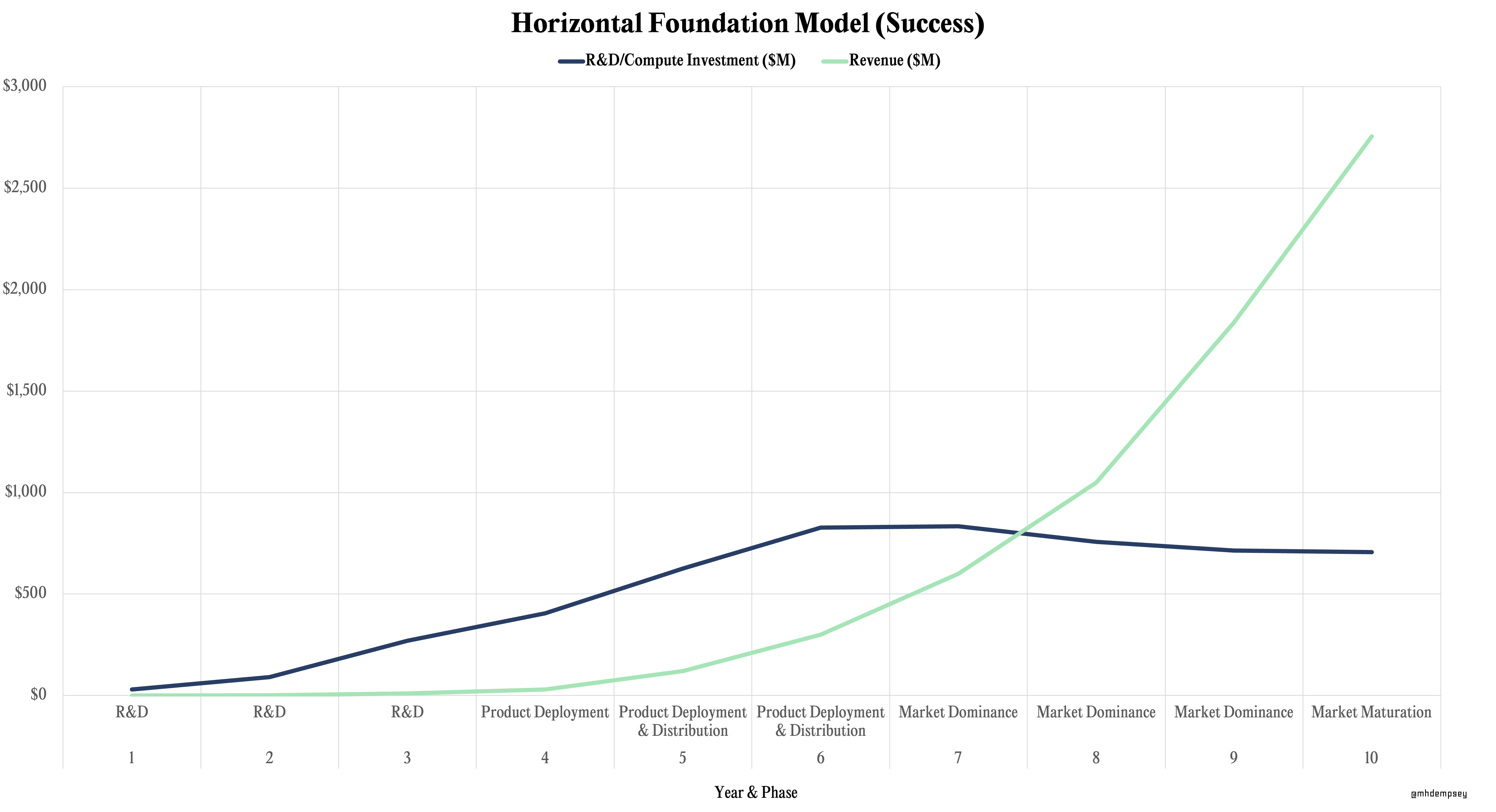
Companies building horizontal foundation models will follow the path of investing heavily in R&D and aggressively deploying models via APIs and products to gain fast, scaled distribution. These companies will likely follow a duopolistic or oligopolistic dynamic in the long-run (as most venture markets do), however the “winners” could take many years to play out due to strong willingness to back companies by investors and an ever-ringing siren song of AGI on the horizon. This will lead to very high annual compute costs, with companies hoping to reach a level of revenue from market dominance that enables them to outpace cumulative R&D costs from retraining, and tailwinds that make inference eventually wildly profitable.
In the above hypothetical chart, we see these numbers more granularly displayed over a 10-year period. These numbers can be scaled up or down theoretically based on just how “horizontal” the model is, as well as the problem space as we move towards multimodal models.
Historical adjacent businesses that match this financing pattern could be Uber, SpaceX, Lime, and perhaps Nvidia, among many others.
While the obvious types of companies that match this path today in AI are OpenAI, Anthropic, Cohere, and Google’s Bard (in some form), it’s likely that we see other adjacencies with similar competition that see large TAM expansion due to novel spending patterns introduced by AI.20Adept is an example of a company that could be this as it could capture a variety of industries with its action driven model
OpenAI in has uniquely progressed on this path already, scaling to 100M+ users on ChatGPT alongside massive revenue ramp, with their competitors aiming to fast-follow in 2024 and 2025.
Vertical Foundation Models
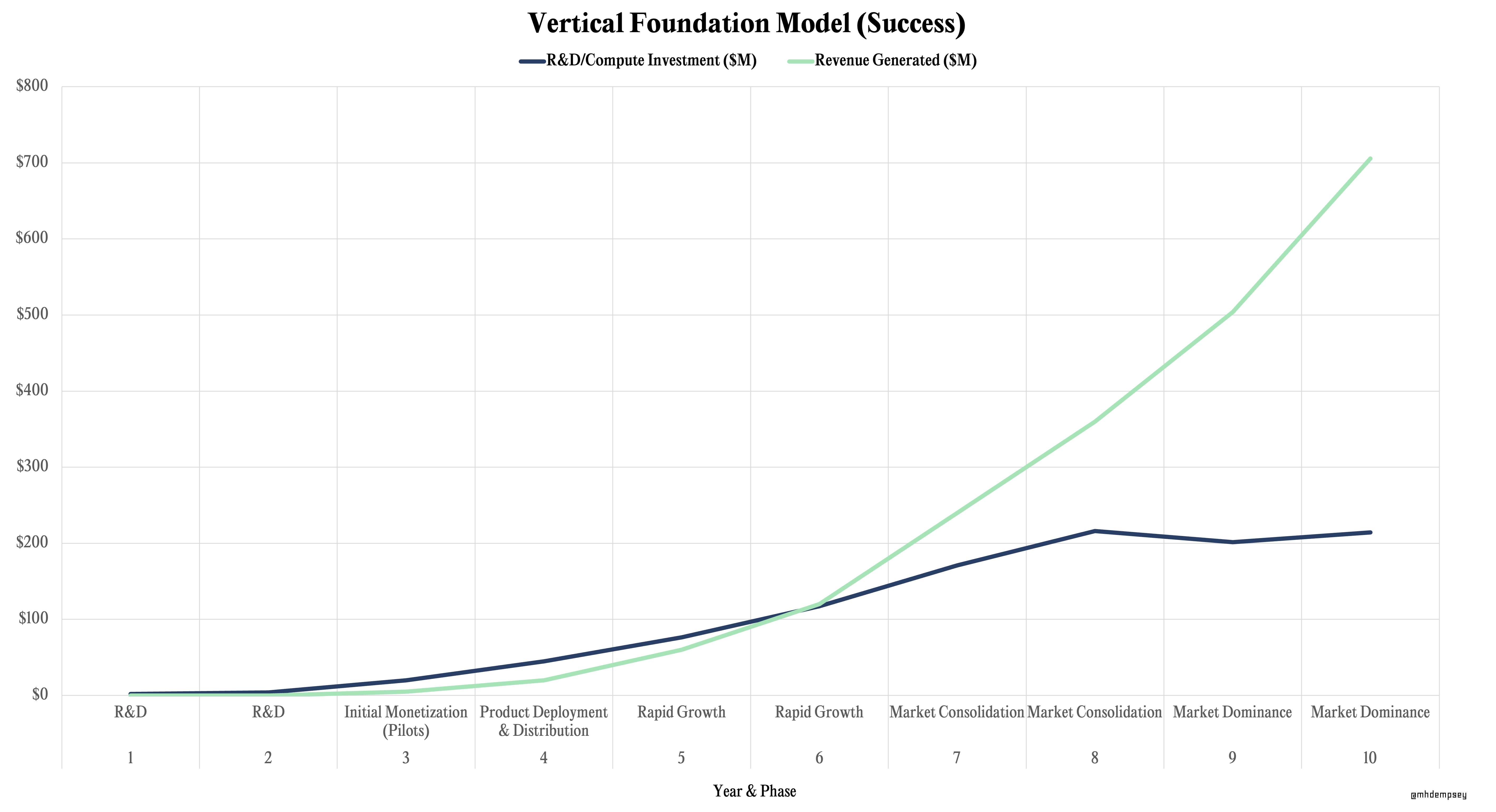
It’s difficult to sum up vertically-focused foundation model company capital constructs due to the massive differences depending on the category or use-case.
Vertical Foundation Model companies could face repeated existential threats over the next few years as startups and incumbents begin to go after every vertical, forcing competing AI startups in certain verticals to spend significant sums of capital trying to push performance as quickly as possible.
That said, I believe it’s more likely that incumbents will move slowly and talent will disperse from the major research labs21The best part of this entire AI run, and perhaps ChatGPT, Dall-E, Stable Diffusion, and more, has been that they created a forcing function for people in research labs to finally get out of paper-only mode and work on solving real problems, allowing academia & open-source to enable companies that are elite at research and customer development to ramp revenue alongside a less costly R&D spend.
With these moving parts, it’s likely that the biggest question in the near-term for these companies will be how to align spending with the strategic decisions we talked about above related to data gathering and customer deployments.
The Gradual Approach: FRom API to Proprietary Models
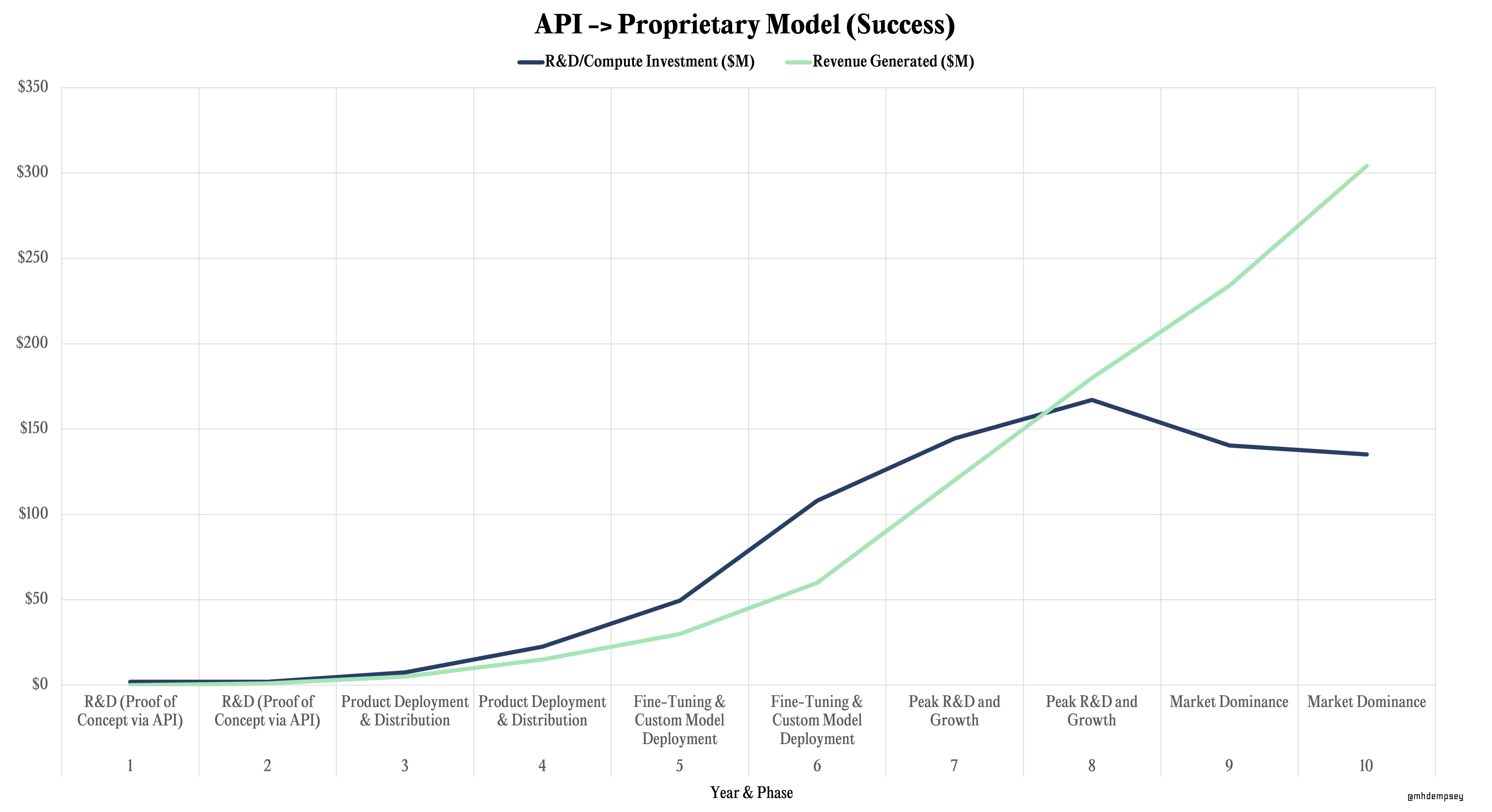
The bulk of this essay has been around companies developing their own models from the start. These naturally carry more capital intensity, should theoretically create deeper moats earlier on and have more shots at flywheels that are durable.
As time progresses, there will be a new wave of companies that are either:
A) being built today on top of existing APIs that eventually realize they should build their own custom models.
or
B) started under the premise of using APIs to ship product before heavily investing in training proprietary models, perhaps waiting for capital intensity to be driven down.
These companies could gain distribution with a core product built around an API, use that distribution to do some fine tuning of models, and then eventually back into more core AI model development.
This strategy likely pattern matches to more traditional software early on, before ramping up to a go/no-go decision ahead of shifting model and compute spend strategy materially.
A counter-point to this strategy is that these companies will be immediately more directly competing with incumbents who can use the same APIs or open-source models as them, but have far greater distribution and data moats.
This leads us to a version of what the “bad outcome” of some of these companies could look like.
Bad Outcomes & False Signals
In a prior post I wrote:
…the actual most dangerous thing an AI/ML investor or founder can do today is mistime progress, misunderstand value accrual, and get trapped by false product-market fit caused more by the ROI of the technology than the ROI of the product.
Since this was published in October 2022, we’ve seen a barrage of financings and acquisitions at Series A+ stages for AI companies that are scaling revenue rapidly (often in similar categories) with varying degrees of credibility around durability of revenue.
This dynamic isn’t unique to AI, as there are a slew of enterprise SaaS businesses that have scaled past $10M ARR only to stall out or churn revenue over time, leading to 10s of millions of dollars of capital being burned as companies try everything to stop the bleeding by spending money far ahead of revenue growth.
That said, AI companies may face a more capital destructive picture.
There will undoubtedly be some companies within AI that think they are building moats by spending an immense amount of money on training, aiming to build the best models for a given use-case. These companies could garner false signals in traction and be destroyed by product churn, higher than expected costs, technological leapfrogging, or a commoditization curve they did not expect.
This will retroactively be described as lighting $2 on fire to get $1 of revenue perpetually, until financing sources dry up, with these companies never reaching the “golden cross” of cumulative revenue surpassing cumulative R&D.
At each type of company this will spell trouble, as there likely will be minimal room for tertiary or third-tier players at each strategy except for perhaps those anchoring on privacy/trust or via decentralized alternatives.
While in the interim this journey will likely create many unicorns, these businesses could be pattern-matched from a narrative and strategy perspective to companies like Kozmo, Bird (raised over $900M), Carvana (raised over $4.8B), and maybe OpenDoor (raised over $1.9B).
Navigating The Unknown

It is yet to be determined if the capital structures and technological forces for AI companies in this cycle will create outsized value. There is plenty of ink to spill about how AI is the next major value creation technology in startups, and equally as much about how incumbents could capture all the value, however the realistic result will be “few do, most don’t” and some euphoric over-investment.22I think you can draw parallels with the On-Demand Economy, where an enabling technology was paired with a ton of capital intensive startups and pitched as the new paradigm. AI is a bit different though as compute costs theoretically directly scale to use-case difficulty where this wasn’t as true with ODE as you had a fixed cost of 1 human hour of labor across all use-cases. Asymmetric Upside thinking is here to stay.
AI companies will either train a model that pays off in an appropriate amount of time, with a revenue ramp that capital markets will find acceptable…or they won’t.
They might spend immense amounts of cash for years and have it eventually pay off once competition is eroded.
They might be perpetual money losing machines where the R&D looks like it’s building value but they can’t create meaningful product lock-in, sustainable economics, or a fast enough flywheel.
The ground might shift beneath them and their core competency might be forced to move from AI development to product to partnerships etc.23We saw a version of this in prior cycles and adjacent areas like AVs where the timing for scaled value for startups was too long and companies pivoted to closed-loop or closed community systems that ultimately were too capital intensive.
We can’t know, but we can hypothesize.
A piece of advice I give founders who are navigating complex idea mazes (most deep tech founders) is to physically write down core hypotheses each month or quarter and revisit them. This enables them to have an unbiased view of their conviction and reasoning, without any revisionist history.
Understanding which path a company is on, and hypothesizing what the product sequence is, matters. It matters because they must have a view on the explicit bets they are making on the commoditization curve, the plateau of value on the AI side, the customers they prioritize, and the market they dominate over time.
By having a hypothesis that is constantly navigating its way through the fog-laden dark forest of AI, it allows companies to be prepared to recognize when things change and how these changes impact their moats, their cost structures, and their ultimate strategies.
Whether it’s new research, new APIs, new competition, new compute,24There’s an interesting world to imagine in which Compute Collectives break out where companies that are non-competitive but perhaps complementary build clusters…talk about how important it is to know your strategy then, or maybe even new financing structures, there are a cascading number of questions that will perpetually arise.
However, in the end, the question all companies must answer is how do they sequence to the future they believe in, how much capital will they deploy to get there, and will it be worth it to stay there?
Recent Comments